
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- ggplot()
- ISLR
- ggplot2
- R 연습문제
- 생존분석
- 주식데이터시각화
- 카플란마이어
- 의사결정나무
- ggsurvplot
- R select
- R 결측치
- Bias-Variance Tradeoff
- R mutate
- 데이터 핸들링
- 콕스비례모형
- R filter
- R
- 이산형 확률분포
- R문법
- 교차타당성
- dplyr
- 강화학습 #추천서적 #강화학습인액션
- R dplyr
- 데이터핸들링
- R ggplot2
- 생존그래프
- 확률실험
- CrossValidation
- 미국 선거데이터
- geom_errorbar
- Today
- Total
Must Learning With Statistics
6. R 중급문법 2단계 본문

Chapter6. R 중급문법 1단계
1. 효과적인 데이터 핸들링을 위한 apply & dplyr 소개
R에는 매우 많은 명령어가 존재하며, 그 중 다수의 코드는 같은 기능을 하지만 명령어만 다를 뿐입니다. 그렇기에, 인터넷에 올라와 있는 R코드들을 살펴보면 작성자의 개성에 따라 다양하게 구성되어 있다는 것을 확인할 수 있습니다. 이는 곧 R의 가장 큰 장점이자 가장 큰 단점으로 작용합니다. 코드를 다양하고 편하게 작성할 수 있기 때문에, 편리와 다양성이 보장된 반면, 처음 접하는 사람들에게는 혼란을 야기하기 매우 좋으며, 정돈되어 있지가 않습니다. python은 numpy, pandas 등의 단일 패키지로 구성되어 있는 점과 비교하면 R은 지나치게 혼란스러울 수 있습니다. 하지만 그렇다고 파이썬이 R보다 쉽다는 의미로 직결되지는 않으니, 편한 마음으로 학습을 하면 됩니다.
이번 챕터의 목적은 통계값을 뽑아낼 때 자주 쓰이는 명령어들을 정리하면서, 같은 기능을 하는 코드들도 다뤄보도록 하겠습니다. 아마, 여기까지 따라오셨다면 이제 R코드의 구조는 다 이해하실 거라고 생각합니다.
이번 챕터에서 주로 다룰 패키지는 다음과 같습니다.
library(dplyr)
library(reshape)
library(plyr)dplyr 및 reshape 패키지는 매우 자주 쓰이는 패키지 입니다. 주로 이 패키지들을 위주로 다뤄보도록 하겠습니다.
2. 데이터 불러오기
HR = read.csv('D:/Dropbox/DATA SET/HR_comma_sep.csv')3. apply 함수와 dplyr 패키지 소개
apply 함수 소개
apply라는 함수는 많은 코드에서 볼 수 있는 함수입니다. 저희는 이전에 for문을 통해 반복문을 만들어 본적이 있습니다. for문은 매우 편리한 기능이지만, 만능은 아닙니다. 그 이유는 하나의 열(Column)에 대해 작동을 할 뿐, 동시에 여러 column 혹은 row에 대해서 계산을 실행할 수는 없기 때문입니다. apply는 이를 동시에 계산 할 수 있도록 도와주는 훌륭한 기능의 함수입니다.
동일한 기능에 대해서 apply문과 for문을 사용할 경우, 명령어가 어떻게 구성이 되는지 보도록 하겠습니다.
문제 : HR 데이터 셋의 1,2열 평균을 구하고자 한다.
- for문을 사용할 경우
for(i in 1:2){
print(paste(colnames(HR)[i],":",mean(HR[,i])))
}[1] "satisfaction_level : 0.612833522234816"
[1] "last_evaluation : 0.716101740116008"- apply를 활용할 경우
apply(HR[,1:2],2,mean)satisfaction_level last_evaluation
0.6128335 0.7161017 먼저, apply문의 경우 (데이터, 계산 기준(1 혹은 2), 함수)를 입력해줍니다. 여기서 ’계산 기준(1 혹은 2)’는 행/열 중 어떤 것을 기준으로 연산을 할지 정해주는 설정값입니다. 만약 1을 입력하면, mean을 각 행(row)별로 계산을 할 것이고, 2를 입력하면 mean을 각 열(column)별로 계산을 진행할 것입니다. 위 명령어는 2를 입력했기 때문에, 각 열(column)의 평균을 계산하였습니다.
- colMeans를 활용할 경우
colMeans(HR[,1:2])satisfaction_level last_evaluation
0.6128335 0.7161017 colMeans는 간단하게 바로 각 변수의 평균을 구해주는 명령어입니다. 정말 간편하지요? 근데 이렇게 간단한 함수가 있는데 왜 굳이 apply문을 활용해야 되는지 의문사항이 생길 수가 있습니다. 평균처럼 명령어가 만들어져 있는 상황이면 굳이 apply문을 활용할 필요가 없습니다. 하지만, 그렇지 않은 경우는 어떻게 해야할까요? 지금 당장만해도 주로 평균과 같이 구하는 표준편차를 각 변수마다 계산해주는 간단한 명령어는 존재하지 않습니다. 함수를 직접 만들어 apply에 적용을 시켜줘야 편하게 값을 구할 수가 있습니다.
apply(HR[,1:2],2,sd)satisfaction_level last_evaluation
0.2486307 0.1711691 바로 이런식으로 말이지요. 그리고 만약 데이터에 결측치가 존재한다면? 여러분도 아시다시피, 결측치가 존재할 경우 R에서 연산함수는 na.rm = TRUE옵션이 존재하지 않으면, 모든 결과값이 NA로 나오게 됩니다.
- 각 변수의 표준편차 구하는 방법
D = c(1,2,3,4,NA)
E = c(1,2,3,4,5)
DF = data.frame(
D = D,
E = E
)먼저, 2개의 열(column)으로 구성된 데이터 셋을 만들었습니다. 이제 apply문으로 각 변수의 표준편차를 구해보도록 하겠습니다.
apply(DF,2,sd) D E
NA 1.581139 보시다시피 결측치(NA)가 포함되어 있는 ’D’변수의 표준편차는 NA로 값이 계산이 되었습니다. 이런 경우, NA를 무시할 수 있는 표준편차 계산 함수를 직접 만들어주어야 합니다.
colSd = function(x){
y = sd(x,na.rm = TRUE)
return(y)
}간단하게 y는 x의 표준편차를 구하며 NA를 무시할 수 있도록 na.rm = TRUE옵션을 추가하였습니다. 그럼 이제 다시, apply문을 활용해보도록 하겠습니다.
apply(DF,2,colSd) D E
1.290994 1.581139 방금 만든 ColSd를 활용해주니 문제가 없이 계산이 잘 되는 것을 확인할 수 있습니다. 이렇게, 편하게 만들어진 명령어도 존재하지만, 상황에 따라서는 명령어가 존재하지 않을 경우도 있기때문에, 항상 유념하고 있으셔야 합니다. 다음으로는 다른 종류의 apply 함수를 알아보도록 하겠습니다.
apply계열 함수 소개
- 그룹간 평균을 구하고 싶은 경우
기초 통계분석을 진행할 경우, 그룹 간 통계값(평균, 표준편차) 등을 구하는 상황은 매우 빈번하게 발생합니다. 이런 경우 tapply를 활용하여 간단하게 구할 수가 있습니다.
tapply(HR$satisfaction_level,HR$left,mean) 0 1
0.6668096 0.4400980 tapply함수를 활용하여 (데이터, 그룹, 연산함수)를 입력해주면 간단하게 그룹 간 통계값을 구할 수가 있습니다.
-
한번에 여러 변수들에 대해 동일 조건을 주고 싶은 경우
이런 경우 lappy함수를 활용하면 비교적 편하게 여러 변수에 대하여 동일 함수를 한번에 적용시킬 수가 있습니다. 예를 들어, 위에서 만들었던 DF데이터 셋에 대하여 1에 해당되면 “A”를 주고자 합니다. 이 경우 각 변수에 대해 변환함수를 입력해주어야 하지만, lapply를 활용하면 그럴 필요가 없어지게 됩니다.
먼저, 일반적인 방법으로 진행하면 이렇게 명령어를 구성해야 됩니다.
DF$D2 = gsub(1,"A",DF$D)
DF$E2 = gsub(1,"A",DF$E)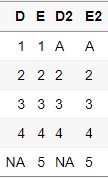
이렇게 하는 것도 나쁘지는 않지만, 만약 적용해야 하는 변수의 갯수가 10개, 20개인 경우는 많이 난감해지는 상황이 오게됩니다. 그럼 이제 lappy를 활용하여 한번에 변경을 시켜보도록 하겠습니다.
DF2 = DF[,1:2]
DF3 = lapply(DF2, function(x) gsub(1,"A",x))
DF3 = as.data.frame(DF3)
lapply 한 줄로 간단하게 코드를 완료했습니다. 이렇게 apply계열은 데이터 핸들링에서 매우 중요한 부분을 차지합니다. 처음에 apply계열 함수를 접하면 매우 어렵지만, 사용하시다보면 익숙해질 것이고, 데이터의 구조를 머리속에 항상 그리고 계시면 어렵지않게 apply계열 명령어를 활용할 수 있으실 것입니다.
dplyr패키지 소개
dplyr패키지는 R 사용자 사이에서 가장 많이 쓰이는 패키지 중 하나입니다. 그 이유는 복잡하고 연쇄적인 연산을 직관적으로 입력하고 수행할 수 있기 때문입니다. 다음의 예시를 한번 살펴보도록 하겠습니다.
head(rowMeans(HR[,1:2]))[1] 0.455 0.830 0.495 0.795 0.445 0.455HR[,1:2] %>%
rowMeans() %>%
head()[1] 0.455 0.830 0.495 0.795 0.445 0.455위 두 명령어는 형태는 다르지만, 동일한 기능을 수행하고 있습니다. 2번째에 해당하는 명령어가 dplyr 패키지의 %>%를 활용한 명령어 구성입니다. 이 매우 이질적이게 생긴 코드는 dplyr 패키지에서 핵심적인 역할을 지니고 있습니다. 먼저, 첫 번쨰 명령어의 실행순서를 살펴보도록 하겠습니다.
head(rowMeans(HR[,1:2]))의 명령어 실행 순서는 다음과 같습니다.
- HR[,1:2] 계산
- rowMeans(HR[,1:2]) 계산
- head(rowMeans(HR[,1:2])) 계산
순서로 연산이 진행이 됩니다. 이 정도야 한 줄로 정리를 할 수 있지만, 만약 명령어를 더 활용해야 하는 경우, 구성이 매우 복잡해질 것입니다. dplyr 패키지의 %>%는 명령어가 복잡해지지 않고 직관적으로 구성이 될 수 있도록 중간다리 역할을 해줍니다.
두번쨰 명령어의 구성을 살펴보시면, 데이터에 대해 의도한 연산 순서대로 명령어를 입력한 것을 확인할 수가 있습니다. 다음의 예를 통해 더 확인해보도록 하겠습니다.
apply(HR[,1:5],2,mean) satisfaction_level last_evaluation number_project
0.6128335 0.7161017 3.8030535
average_montly_hours time_spend_company
201.0503367 3.4982332 colMeans(HR[,1:5]) satisfaction_level last_evaluation number_project
0.6128335 0.7161017 3.8030535
average_montly_hours time_spend_company
201.0503367 3.4982332 HR[,1:5] %>%
colMeans() satisfaction_level last_evaluation number_project
0.6128335 0.7161017 3.8030535
average_montly_hours time_spend_company
201.0503367 3.4982332 이제 %>%의 목적이 어떤 것인지 아시겠나요?? dplyr의 %>%는 언뜻 보면 매우 어려워 보이지만, 생각보다 간단한 것을 알 수 있습니다. 그럼 계속 기존 R코드와 %>%를 사용했을 때의 차이점을 비교해보도록 하겠습니다.
- 데이터 집계 내기
# Summarise
summarise(HR, MEAN = mean(satisfaction_level),
N = length(satisfaction_level)) MEAN N
1 0.6128335 14999HR %>%
summarise(MEAN = mean(satisfaction_level),
N = length(satisfaction_level)) MEAN N
1 0.6128335 14999- subset 후 ddply를 적용했을때 %>% 활용법
# library(plyr)
HR2_O = ddply(subset(HR,left == 1),c("sales"),
summarise,
MEAN = mean(satisfaction_level),
N = length(satisfaction_level))
HR2_D = HR %>%
subset(left == 1) %>%
group_by(sales) %>%
dplyr::summarise(MEAN = mean(satisfaction_level),
N = length(satisfaction_level))
- 새로운 변수를 추가하고 싶은 경우
HR3_D = HR2_D %>%
mutate(percent = MEAN / N)
- dplyr와 ggplot2의 조합
library(ggplot2)
HR2_D %>%
ggplot() +
geom_bar(aes(x=sales,y=MEAN,fill=sales), stat="identity") +
geom_text(aes(x=sales,y= MEAN+0.05,
label=round(MEAN,2))) +
theme_bw() +
xlab("부서") + ylab("평균 만족도") + guides(fill = FALSE) +
theme(axis.text.x = element_text(angle = 45, size = 8.5,color = "black",
face = "plain", vjust = 1, hjust = 1))
4. 중복데이터 제거하기 및 데이터 프레임 정렬
흔하지는 않지만, 중복으로 입력되는 데이터 셋을 마주치는 일이 생기기 마련입니다. 보통 중복데이터는 데이터 수집단계에서 많이 발생합니다. 하지만 이를 하나하나 엑셀로 처리하는 것은 한계가 있기때문에, R에서 처리하는 방법에 대해 다루어 보고자 합니다.
1차원 벡터, 리스트에서의 중복 제거
A = rep(1:10, each = 2) # 1 ~ 10까지 2번씩 반복
print(A) [1] 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10# 중복 제거
unique(A) [1] 1 2 3 4 5 6 7 8 9 101차원 벡터의 경우, unique 명령어를 활용하면, 손쉽게 중복값을 제거할 수가 있습니다.
데이터 프레임에서의 중복 제거
다음과 같은 데이터 프레임을 예시로 삼겠습니다.
# 데이터 불러오기
DUPLICATE = read.csv("D:\\Dropbox\\DATA SET(Dropbox)\\DUPLICATED.csv")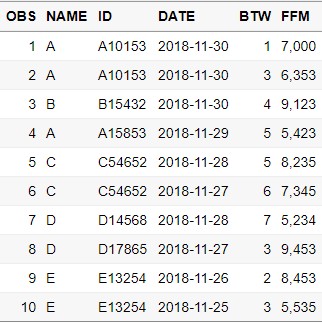
변수의 구성은 다음과 같습니다.
- OBS : 번호
- NAME : 환자 이름
- ID : 환자 고유번호
- DATE : 검사 날짜
- BTW : Body total water
먼저 환자 이름이 있고, 그 환자의 고유 ID가 있습니다. 동명이인은 많기 때문에 항상 고유 ID를 기록해두기 마련입니다.
- 전체 중복 제거
DUPLICATED3_1 = DUPLICATE[-which(duplicated(DUPLICATE)),]
하나라도 중복이 되면 전부 지워버립니다. 별로 추천드리지는 않습니다.
- 변수 한개를 기준으로 중복 제거
# NAME이 같은 변수들 중복 제거
DUPLICATED3_2 = DUPLICATE[-which(duplicated(DUPLICATE$NAME)),]
여기서 주목해야 될 부분은 중복값은 제거를 하고 하나만 남기게 되는데, 그 기준은 Row 번호가 빠른, 즉 위에 있는 행을 남기고 뒤에 있는 데이터 값들을 삭제 시킵다는 것입니다.
- 다변수를 기준으로 중복 제거
#NAME, ID 두 개의 값이 같은 중복 데이터 제거
# 변수명으로 제거
DUPLICATED3_3 = DUPLICATE[!duplicated(DUPLICATE[,c('NAME','ID')]),] 
# 변수인덱스로 제거
DUPLICATED3_4 = DUPLICATE[!duplicated(DUPLICATE[,c(2,3)]),] 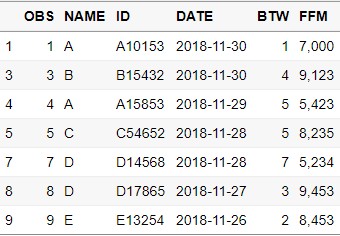
여러 변수들을 기준으로 중복 데이터를 삭제하는 경우도 간단합니다. 대신, 행(row) 인덱스에 중복 제거 조건을 주어야 하는 부분이 조금 복잡해 보일 수는 있지만, 천천히 살펴보시면 크게 어렵지 않다는 것을 확인할 수 있으실 것입니다.
추가적으로 가끔 병원에서는 동일 환자가 같은 검사를 날짜를 달리하여 여러 번 받는 경우가 있습니다. 물론 어떤 값을 남겨야 할지는 상황마다 다르겠지만, 지금은 ’마지막 검사 기준 데이터’를 남기는 것으로 진행하도록 하겠습니다. 중복 제거는 맨 처음값만 남기기 때문에, 최근 검사 데이터가 맨 위로 올라오도록 정렬(sort)을 해주어야 합니다.
- 데이터 정렬하기
# 날짜 변수 설정하기
DUPLICATE$DATE = as.Date(DUPLICATE$DATE,"%Y-%m-%d")
summary(DUPLICATE$DATE) Min. 1st Qu. Median Mean 3rd Qu.
"2018-11-25" "2018-11-27" "2018-11-28" "2018-11-28" "2018-11-29"
Max.
"2018-11-30" 0먼저, 날짜를 기준으로 데이터를 정렬하기 위해서는 DATE 변수가 날짜로 인식이 되어 대소 비교를 할 수 있도록 변수의 strings가 변경이 되어야 합니다. 날짜 변수를 날짜형식으로 바꾸는 명령어는 as.Date, as.Posixct가 있습니다. 보통 ’년-월-일’로 구성되어 있으면 as.Date를 사용하고 ’년-월-일 시:분:초’로 구성되어 있으면 as.Posixct를 쓰게 됩니다. 지금은 ’년-월-일’이기 때문에 as.Date를 사용하도록 하겠습니다.
# DATE변수 기준으로 정렬
DUPLICATE_SORT = DUPLICATE[order(DUPLICATE[,'DATE'],decreasing = TRUE), ]decreasing 옵션은 오름차순 혹은 내림차순으로 할 것인지 정의해주는 것입니다. decreasing = TRUE은 내림차순으로 진행한다는 의미입니다. 중복제거는 위에서 진행했던 것처럼 진행하면 되겠습니다.
병원에서 같은 환자가 여러 검사를 받는 경우는 매우 흔합니다. 그리고 각 검사 수치를 가지고 분석을 해야 되지요. 하지만 데이터 수집이 조금은 애매하게 되어 있는 경우가 종종 발생합니다. 바로 이런 경우와 같습니다. TEST 변수는 검사 종류라고 보면 됩니다. 수집체계가 잘못된 것은 아니지만, 각 검사 수치를 모델링에서 써먹으려면, TEST의 각 수준(levels, T1,T2,T3,T4)는 하나의 TEST변수가 아닌 각각의 T1, T2, T3, T4 변수로 잡혀야 합니다.
이렇게 각 검사 수치가 변수가 되어야 후에 모델링에 사용할 수 있습니다. 다음의 코드는 이렇게 되어 있습니다.
library(reshape)
RESHAPE = read.csv("D:\\Dropbox\\DATA SET(Dropbox)\\RESHAPE.csv")
CAST_DATA = cast(RESHAPE,OBS + NAME + ID + DATE ~ TEST)
reshape 라이브러리는 데이터 프레임의 형태를 바꾸고 싶을 때 주로 사용하는 패키지입니다. 이렇게 TEST의 각 수준(levels)이 변수가 되었을 때, 이런 형태를 Wide Form이라고 합니다. 반대로, 기존에 하나의 TEST 변수로 구성이 되었을 경우 Long Form형태라고 합니다. 다시 원래대로 돌아가는 방법은 다음과 같습니다.
MELT_DATA = melt(CAST_DATA,id=c("OBS","NAME","ID","DATE"))
MELT_DATA = na.omit(MELT_DATA)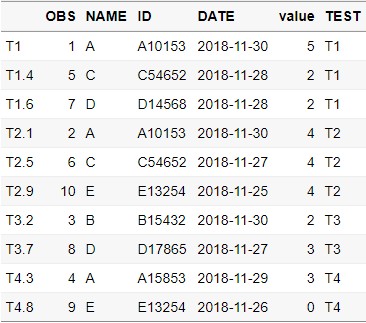
melt함수를 이용하면, 다시 원래대로 돌아올 수가 있습니다. Wide & Long Form을 이해하는 것은 데이터핸들링 단계에서 매우 중요하므로 충분한 연습이 필요한 부분입니다.
추가로 두 형태의 데이터 모두 쓰임이 다릅니다.
- CAST_DATA의 경우, 그래프 시각화할 때의 데이터 구조로 적합합니다.
- MELT_DATA의 경우, 모델링 할 때의 데이터 구조로 적합합니다.
5. 데이터 합병하기(merge)
데이터를 분석하다보면, 특정 KEY값으로 데이터를 합병해야 될 때가 있습니다.

방법은 다음과 같습니다.
### 이전 데이터 작업 코드
DUPLICATE = read.csv("D:\\Dropbox\\DATA SET(Dropbox)\\DUPLICATED.csv")
DUPLICATED3_3 = DUPLICATE[!duplicated(DUPLICATE[,c('NAME','ID')]),]
RESHAPE = read.csv("D:\\Dropbox\\DATA SET(Dropbox)\\RESHAPE.csv")
CAST_DATA = cast(RESHAPE,OBS + NAME + ID + DATE ~ TEST)
### 데이터 합병
MERGE = merge(DUPLICATED3_3,CAST_DATA[,c(-1,-2,-4)] , by = "ID",
all.x = TRUE)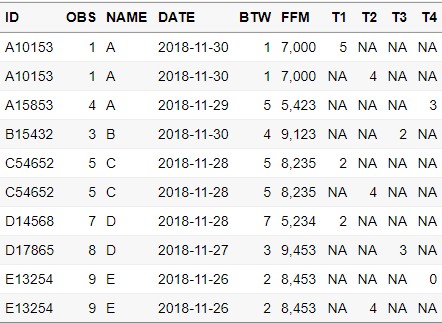
6. 연습문제
-
Event_Time.csv를 불러오시오.
링크 : https://www.dropbox.com/sh/xx1w2syi768kfu0/AACZgxgo1fcxyDMgv9U-iTz8a?dl=0 -
colSums를 활용하여 Alarm, Event변수의 합을 각각 구하시오.
-
reshape 패키지의 함수를 활용하여 다음의 데이터 셋을 만들어보시오.

'MustLearning with R 1편' 카테고리의 다른 글
| 8. R 데이터 시각화 (0) | 2020.01.29 |
|---|---|
| 7. R 중급문법 3단계 (0) | 2020.01.29 |
| 5. R 기본문법 4단계 (2) | 2020.01.29 |
| 4. R 기본문법 3단계 (0) | 2020.01.29 |
| 3. R 기본문법 2단계 (1) | 2020.01.29 |



