
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 생존그래프
- ggplot2
- 데이터핸들링
- 데이터 핸들링
- 콕스비례모형
- 의사결정나무
- 확률실험
- R 결측치
- dplyr
- 생존분석
- R 연습문제
- R ggplot2
- R문법
- 미국 선거데이터
- ggplot()
- 이산형 확률분포
- 교차타당성
- R mutate
- R filter
- 카플란마이어
- ISLR
- ggsurvplot
- R
- R select
- 주식데이터시각화
- geom_errorbar
- Bias-Variance Tradeoff
- 강화학습 #추천서적 #강화학습인액션
- CrossValidation
- R dplyr
- Today
- Total
Must Learning With Statistics
7. R 중급문법 3단계 본문

Chapter7. R 중급문법 2단계
이번 장에서는 이전에 다루었던 dplyr를 조금 더 심도 있게 다룹니다.
0. 데이터 불러오기
다운로드 링크 : 추가 예정
library(dplyr)STOCK = read.csv("D:\\Dropbox\\DATA SET(Dropbox)\\Uniqlo_stocks2012-2016.csv")
STOCK$Date = as.Date(STOCK$Date)
STOCK$Year = as.factor(format(STOCK$Date,"%Y"))
STOCK$Day = as.factor(format(STOCK$Date,"%a"))
str(STOCK)'data.frame': 1226 obs. of 9 variables:
$ Date : Date, format: "2016-12-30" "2016-12-29" ...
$ Open : int 42120 43000 43940 43140 43310 43660 43900 42910 42790 43350 ...
$ High : int 42330 43220 43970 43700 43660 43840 44370 43630 43150 43550 ...
$ Low : int 41700 42540 43270 43140 43090 43190 43610 42860 42740 42810 ...
$ Close : int 41830 42660 43270 43620 43340 43480 44000 43620 43130 43130 ...
$ Volume : int 610000 448400 339900 400100 358200 381600 658900 499400 358700 542000 ...
$ Stock.Trading: num 2.56e+10 1.92e+10 1.48e+10 1.74e+10 1.55e+10 ...
$ Year : Factor w/ 5 levels "2012","2013",..: 5 5 5 5 5 5 5 5 5 5 ...
$ Day : Factor w/ 5 levels "금","목","수",..: 1 2 3 5 4 2 3 5 4 1 ...1. 집계 데이터 만들기
원하는 그래프를 그리려고 하다 보면, 가끔 데이터의 집계된 결과를 통해 그래프를 작성해야 될 떄가 있습니다. dplyr을 활용하면 데이터 집계 과정과 시각화 과정을 함께 할 수 있습니다. 시각화를 다루기 전에, 자주 쓰이는 dplyr 명령어들을 다루도록 하겠습니다.
group_by
집계 기준 변수를 정해주는 명령어입니다.
summarise
집계 기준 변수 및 명령어에 따라 요약값을 계산합니다.
Group_Data = STOCK %>%
group_by(Year,Day) %>%
summarise(Mean = round(mean(Open)),
Median = round(median(Open)),
Max = round(max(Open)),
Counts = length(Open))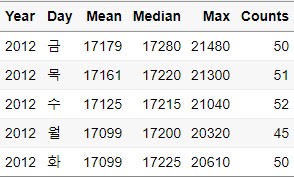
ungroup
group으로 묶인 데이터를 그룹 해제 시켜주는 명령어입니다.
ungroup을 해주는 이유
- group_by를 통해 발생할 수 있는 error 방지를 합니다.
Error in mutate_impl(.data, dots) : Column
Classcan’t be modified because it’s a grouping variable
-
group_by 여부에 따라 결과가 다르게 나옵니다.
-
[]안에 조건을 줄 때, 함수가 안먹히는 경우가 발생합니다.
Ungroup_Data = Group_Data %>%
ungroup()str(Group_Data)Classes 'grouped_df', 'tbl_df', 'tbl' and 'data.frame': 25 obs. of 6 variables:
$ Year : Factor w/ 5 levels "2012","2013",..: 1 1 1 1 1 2 2 2 2 2 ...
$ Day : Factor w/ 5 levels "금","목","수",..: 1 2 3 4 5 1 2 3 4 5 ...
$ Mean : num 17179 17161 17125 17099 17099 ...
$ Median: num 17280 17220 17215 17200 17225 ...
$ Max : num 21480 21300 21040 20320 20610 ...
$ Counts: int 50 51 52 45 50 51 51 50 42 51 ...
- attr(*, "groups")=Classes 'tbl_df', 'tbl' and 'data.frame': 5 obs. of 2 variables:
..$ Year : Factor w/ 5 levels "2012","2013",..: 1 2 3 4 5
..$ .rows:List of 5
.. ..$ : int 1 2 3 4 5
.. ..$ : int 6 7 8 9 10
.. ..$ : int 11 12 13 14 15
.. ..$ : int 16 17 18 19 20
.. ..$ : int 21 22 23 24 25
..- attr(*, ".drop")= logi TRUEstr(Ungroup_Data)Classes 'tbl_df', 'tbl' and 'data.frame': 25 obs. of 6 variables:
$ Year : Factor w/ 5 levels "2012","2013",..: 1 1 1 1 1 2 2 2 2 2 ...
$ Day : Factor w/ 5 levels "금","목","수",..: 1 2 3 4 5 1 2 3 4 5 ...
$ Mean : num 17179 17161 17125 17099 17099 ...
$ Median: num 17280 17220 17215 17200 17225 ...
$ Max : num 21480 21300 21040 20320 20610 ...
$ Counts: int 50 51 52 45 50 51 51 50 42 51 ...str을 통해 Group_Data와 Ungroup_Data를 비교해보면, 생긴 것은 똑같지만 내부 타입이 다르다는 것을 확인할 수 있습니다. 또한 기본적으로 data.frame형태가 아닌 것을 확인할 수가 있습니다. R을 처음 시작하는 입장에서는 이러한 사소한 차이에서 발생하는 오류 때문에 크게 고생하는 경우가 자주 있습니다. 그러니 분석을 시작할 때는 as.data.frame을 통해 꼭 data.frame형태의 strings로 변경해주시길 바랍니다.
count
집계 기준에 따라 데이터의 row 갯수를 계산해줍니다. summarise 내에서 쓰인 length와 비슷한 같은 기능을 수행합니다.
Count_Data = STOCK %>%
group_by(Year,Day) %>%
count()2. 조건에 따라 데이터 추출하기
원하는 조건에 따라 데이터를 추출하는 명령어입니다. filter(), subset()을 활용하면 됩니다. 두 명령어 모두 같은 기능을 수행하니 편하신 명령어를 사용하면 됩니다.
Subseted_Data = Group_Data %>%
filter(Year == "2012")
head(Subseted_Data)# A tibble: 5 x 6
# Groups: Year [1]
Year Day Mean Median Max Counts
<fct> <fct> <dbl> <dbl> <dbl> <int>
1 2012 금 17179 17280 21480 50
2 2012 목 17161 17220 21300 51
3 2012 수 17125 17215 21040 52
4 2012 월 17099 17200 20320 45
5 2012 화 17099 17225 20610 503. 데이터 중복 제거하기
데이터에 내에 존재하는 중복데이터를 제거합니다. 명령어는 distinct()를 사용합니다.
# 중복 데이터 생성
SL = sample(1:nrow(Group_Data),500,replace = TRUE)
Duplicated_Data = Group_Data[SL,]Group_Data는 25개의 행(row)로 구성되어 있으나, 중복을 허용하여 500개로 증가시켜버리면 중복데이터가 무조건 발생하게 됩니다.
Duplicated_Data2 = Duplicated_Data %>%
distinct(Year,Day,Mean,Median,Max,Counts)4. 샘플 데이터 무작위 추출
데이터의 행이 너무 많은 경우, 그래프를 그릴 때 연산속도가 오래 걸리며, R이 다운될 수 있는 문제가 있습니다. 그런 경우, 무작위로 샘플 데이터를 뽑아, 가볍게 시각화를 하는 것도 좋은 방법입니다. 명령어는 sample_frac(), sample_n()을 사용합니다. frac은 size에서 비율(0 ~ 1)을, n은 행의 갯수를 입력합니다.
참고할 부분은 group지정 여부에 따라 sample 결과가 다르게 나타납니다.
sample_frac() - 그룹이 지정되어 있는 데이터
Sample_Frac_Gr = Group_Data %>%
sample_frac(size = 0.4, replace = FALSE)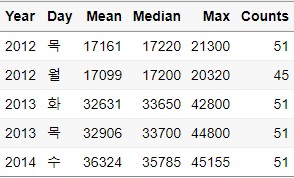
각 년도에서 2개씩 균형있게 sampling된 것을 확인할 수 있습니다.
- 그룹이 해제되어 있는 데이터
Sample_Frac_Un = Ungroup_Data %>%
sample_frac(size = 0.4, replace = FALSE)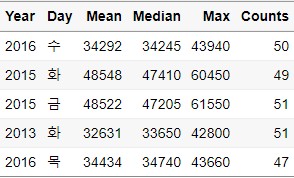
**
sample_n()**
Sample_N_Gr = Group_Data %>%
sample_n(size = 5, replace = FALSE)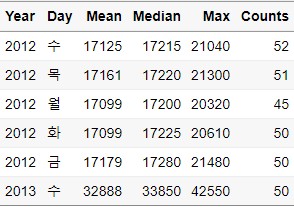
각 년도별 2개씩 뽑힌 것을 확인할 수 있습니다. group이 적용되어 있는 경우에는 현재 데이터에서는 size 값을 5보다 큰 숫자를 설정할 수가 없습니다. (각 년도별 5개씩 데이터가 있기 때문)
Sample_N_Un = Ungroup_Data %>%
sample_n(size = 10, replace = FALSE)
제가 입력한 size값에 따라서 무작위로 10개가 뽑힌 것을 확인할 수 있습니다.
중복 제거를 한 후, 데이터의 행(row)이 25로 돌아온 것을 확인할 수 있습니다.
5. 정해진 Index에 따라 데이터 추출하기
무작위 추출이 아닌, 순서대로 뽑거나 원하는 구간만 설정해서 데이터를 뽑아내는 방법입니다. 명령어는 slice(), top_n()이 있습니다.
slice()
slice()는 Index를 직접 설정함으로, 원하는 구간만 추출할 수 있습니다. 이때 Dataset은 ungroup()이 되어 있는 데이터로 진행해야 됩니다.
Slice_Data = Ungroup_Data %>%
slice(1:10)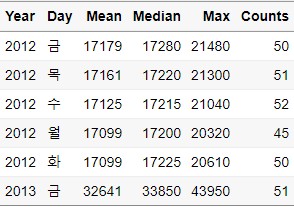
**
top_n()**
top_n()은 설정해준 변수를 기준으로 가장 값이 높은 n개의 데이터를 가져옵니다.
Top_n_Data = Ungroup_Data %>%
top_n(5,Mean) # Mean이 가장 높은 5개 데이터 추출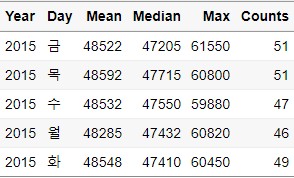
6. 데이터 정렬하기
데이터를 특정 변수를 기준으로 정렬하는 방법입니다. arrange()를 이용합니다. 마찬가지로 ungroup()이 설정된 데이터로 정렬합니다. 만약 group_by()가 설정되어 있는 데이터를 기준으로 정렬 할 경우, Year별로 정렬합니다.
- 오름차순
# ungroup으로 그룹지정을 해제한 데이터
Asce_Data = Ungroup_Data %>%
arrange(Mean) # Mean을 기준으로 오름차순 정렬
년도에 상관없이 정렬되는 것을 확인할 수 있습니다.
# group이 지정되어 있는 데이터
Asce_Data2 = Group_Data %>%
arrange(Mean) 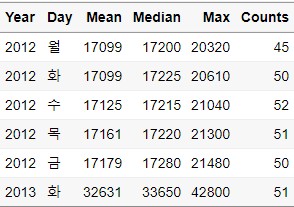
년도에 따라 정렬되는 것을 알 수 있습니다.
- 내림차순
내림차순은 변수에 ’-’를 붙여주면 됩니다.
Desc_Data = Ungroup_Data %>%
arrange(-Mean)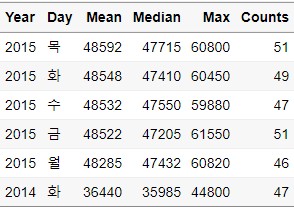
7. 원하는 변수(Colomn)만 뽑아내기
데이터를 핸들링 할 때, 모든 변수들을 가져갈 필요는 없습니다. 이런 경우 select(), select_if()를 활용하여 원하는 변수들을 뽑아낼 수 있습니다.
select()
select()를 통해 원하는 변수를 뽑아낼 수 있습니다. 인덱스를 통해 뽑아도 되고, 변수명을 입력해서 뽑아내도 됩니다. 편하신 방법대로 하시면 됩니다.
# Index 활용
Select_Data = Group_Data %>%
select(1:2)
# Column명 활용
Select_Data = Group_Data %>%
select(Year,Day)
**
select_if()**
select_if()를 통해 뽑는 조건을 줄 수 있습니다. 예를 들어, 데이터 타입에 따라 뽑아낼 수 있습니다.
# Factor 변수만 뽑기
Select_if_Data1 = Group_Data %>%
select_if(is.factor)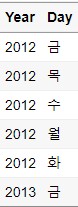
데이터 타입이 Factor인 변수만 뽑아서 데이터 셋을 만든 것을 확인할 수 있습니다.
# integer 변수만 뽑기
Select_if_Data2 = Group_Data %>%
select_if(is.integer)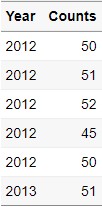
8. 새로운 변수 만들기 혹은 한번에 처리하기
데이터 핸들링 과정에서 새로운 변수(Column)를 만들고자 할 때 필요한 기능입니다. 대표적으로는 mutate(), mutate_if(), mutate_at()이 있습니다.
mutate()
mutate()는 하나의 변수를 명령어에 따라 추가하는 방법입니다.
Mutate_Data = STOCK %>%
mutate(Divided = round(High/Low,2)) %>%
select(Date,High,Low,Divided)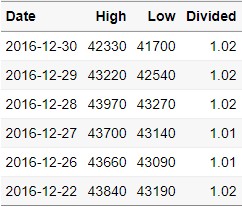
**
mutate_if()**
mutate_if()은 지정해준 모든 변수에 대해 계산식을 적용시켜 줍니다. 예를 들어, 데이터의 타입을 변경하고 싶을 때, as.factor()같은 명령어를 하나씩 적용시키는 방법은 시간을 많이 잡아먹는 노가다 작업입니다. 이런 경우, mutate_if()를 통해 한번에 데이터 타입을 변경시켜줄 수 있습니다.
# integer 타입 변수를 모두 numeric으로 변경
Mutate_If_Data = STOCK %>%
mutate_if(is.integer,as.numeric) 
**
mutate_at()** mutate_at()은 지정한 변수들에 대해 계산식을 적용시키는 명령어입니다.
Mutate_At_Data = STOCK %>%
mutate_at(vars(-Date,-Year,-Day),log) %>%
select_if(is.numeric)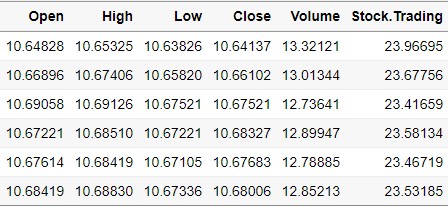
Date, Year, Day 변수를 제외하고 나머지 변수들은 모두 log 변환이 적용된 것을 확인할 수 있습니다.
여기까지 dplyr의 활용법을 다루었습니다. 모든 기능을 다룬 것은 아니고, 제 경험상 많이 썼던 기능들을 위주로 선별하였습니다. dplyr로 핸들링 한 후, %>%를 이용하여 바로 ggplot() 명령어와 연계할 수 있기 때문에 매우 효율적으로 작업을 할 수 있습니다.
9. 연습문제
-
HR 데이터에 Factor 변수들만 뽑아, HR_Factor라는 데이터 프레임을, Numeric 변수들만 뽑아 HR_Numeric 데이터를 생성하시오.
-
HR 데이터의 sales, left 변수를 기준으로 satisfaction_level, last_evaluation의 평균, 중위수, 표준편차값을 계산해서 HR_summarise라는 데이터 프레임을 만드시오.
'MustLearning with R 1편' 카테고리의 다른 글
| 9. ggplot2를 활용한 다양한 그래프 그리기 (0) | 2020.01.29 |
|---|---|
| 8. R 데이터 시각화 (0) | 2020.01.29 |
| 6. R 중급문법 2단계 (0) | 2020.01.29 |
| 5. R 기본문법 4단계 (2) | 2020.01.29 |
| 4. R 기본문법 3단계 (0) | 2020.01.29 |



