
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Bias-Variance Tradeoff
- 교차타당성
- ggplot()
- 카플란마이어
- 확률실험
- 데이터핸들링
- geom_errorbar
- 생존분석
- 미국 선거데이터
- 주식데이터시각화
- CrossValidation
- 의사결정나무
- 강화학습 #추천서적 #강화학습인액션
- 데이터 핸들링
- dplyr
- R dplyr
- R filter
- R 결측치
- R
- R mutate
- R select
- R 연습문제
- 생존그래프
- 콕스비례모형
- 이산형 확률분포
- ggsurvplot
- ggplot2
- ISLR
- R문법
- R ggplot2
- Today
- Total
Must Learning With Statistics
13. 기초통계 이론 3단계 본문

Chapter13. 기초통계이론 3단계
최소제곱법을 사용하는 일반적 회귀분석과 달리 GLM에서는 가정된 분포하에서 모형을 추정합니다. 이를 최대가능도법이라고 하는데 가능도(likelihood)라는 가능성의 개념을 이용한 추정방법입니다. 이 가능도라는 개념은 분포 가정만 합리적이라면 매우 파워풀하고 유용한 개념으로 통계 전체를 아우르고 있습니다. 이번 장에서는 가능도에 대한 개념과 가능도를 이용한 변수 선택(모형 선택) 방법을 다루겠습니다.
1. 가능도와 가능도함수
가능도(likelihood)는 가능성 혹은 공산이라는 의미를 갖고 있습니다. 조금 더 풀어서 말씀드리면 가정된 분포에서 주어진 데이터가 나올 가능성이라고 할 수 있습니다. 예를 들어 \(N(\mu, \sigma^2 )\) 라는 정규분포를 따를 것으로 가정되는 모집단에서 추출된 표본들을 얻었을 때, 그 표본 값들과 정규분포의 확률함수를 이용하면 평균이 \(\mu\) 이고 분산이 \(\sigma^2\)가 맞을 가능성을 확인할 수 있습니다. 이 가능성이라는 것은 결국 주어진 표본들에서 확률함수를 통해 산출되므로 조건부 확률값이라는 관점으로 볼 수 있고 데이터가 주어진 모든 환경에 적용할 수 있습니다.
가능도라는 개념을 이해하기 위해서는 확률과의 차이점을 이해하면 쉽습니다.
간단한 동전던지기 실험을 10번 진행했을 때 앞면이 4번 나왔습니다. 이런 경우를 가정했을 때
- 확률 : 앞면이 나올 확률은 0.4입니다. 즉, 확률은 확률실험의 결과를 집계한 것이라고 볼 수 있습니다.
- 가능도 : 동전을 10번 던졌을 때 앞면이 나올 확률에 따라서 앞면이 4번 나올 가능성입니다.
여기서 가능도 값을 계산하는 함수를 가능도 함수(Likelihood function)라고 합니다. 동전던지기 실험을 기반으로 가능도 함수를 계산하면 다음과 같습니다.
동전 던지기 실험은 이항분포를 따르니 확률질량함수(\(pmf\))는 \({n}\mathrm{C}{x} p^x(1-p)^{n-x}\)입니다.
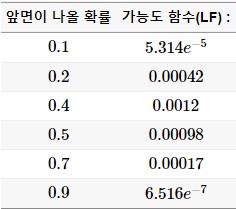
위의 표처럼 앞면이 나올 확률에 따라 10번 중 4번이 앞면이 나올 가능성을 구한 것이 가능도 함수(Likelihood function)라고 합니다. 가능함수를 계산하기 위해서는 가정된 분포, 조사된 표본이 필요하고 조건부적 성격을 제외하면 확률함수와 정확히 동일합니다. 다만 관점을 달리는 것 뿐입니다. 확률함수에서 확률변수는 이미 조사되어 주어진 값이 되고 정해져있던 모수가 함수의 인수가 됩니다.
모집단의 확률함수가 \(f\) 라고 알려져 있고 그 확률함수의 모수를 \(\theta\) 라고 합시다. 그렇다면 이 확률함수를 \(f(Y;\theta)\) 라고 표현할 수 있을 것입니다. 이 모집단에서 \(y\)라는 표본이 나왔다고 하면 가능도함수 \(L\)은 다음과 같이 정의됩니다. \[ L(\theta ;y)= f(\theta\;| \; y) \] 이는 표본이 한 개가 아니었을 때도 마찬가지입니다. 독립적으로 추출된 표본이 \(y_1 , y_2, \cdots y_n\) 이라고 하면 각 표본들의 모집단의 확률함수는 전부 \(f(Y;\theta)\) 가 될 것이고 독립적으로 추출되었으므로 확률의 곱법칙에 의해 결합확률함수를 구할 수 있습니다. 즉, \(\prod_i^n f(Y_i;\theta)\) 와 같이 표현됩니다. 이를 이용하면 \(n\)개의 표본에서의 우도함수도 어렵지 않게 정의할 수 있습니다.
\[ L(\theta \; ; y_1 ,y_2,\cdots ,y_n) = \prod_{i=1}^n f(\theta \; | \; y_1 ,y_2,\cdots ,y_n ) \] 또한 실제로 활용할 때는 계산과 편의를 위해 일반적으로 가능도함수에 로그함수를 씌워 사용하게 됩니다. 이를 로그가능도함수(log-likelihood function)라고 부르며 소문자로 표현합니다. 로그함수는 단조증가함수이기 때문에 가능도함수 값이 커지면 로그가능도함수 값도 항상 커집니다.
2. 최대가능도 추정량(Maximum Likelihood Estimation, MLE)
로지스틱 회귀모형을 다룰 때, 로지스틱 모형과 같은 GLM은 최소제곱법이 아닌 최대가능도추정법을 이용한다고 했습니다. 이 최대가능도추정량에 의해 추정된 추정량을 최대가능도추정량(maximum likelihood estimator) 이라고 부르며 흔히 줄여서 MLE라고 표현합니다. MLE는 역시 가능도함수의 개념만 잘 알고 있다면 어렵지 않은 개념입니다. 가정된 확률분포의 모수 \(\theta\) 가 될 수 있는 수많은 후보들 중 로그가능도함수(혹은 우도함수)를 최대로하는 후보를 모수의 추정량으로 선택하는 방법입니다. 로그가능도함수 값이 크다는 것은 그만큼 주어진 데이터에 적합하는 것을 의미하기 때문에 MLE는 충분히 합리적인 추정량입니다. GLM에서도 기울기와 절편 역시 이런식으로 가정된 분포와 주어진 데이터에서 로그가능도함수를 가장 크게하는 값으로 적합시킵니다.
이렇게 구해진 \(MLE\)는 \(n\)이 많아짐에 따라 통계검정에 사용되는 정규근사가 가능하며 그 외에도 효율성, 불편성이라는 좋은 성질들이 생기게 되어 매우 자주 사용되는 방법입니다. 앞서 다룬 동전 던지기 실험 예시를 들면 10번 중 4번이 나올 가능성이 가장 높은 확률은 0.4일 때입니다. 이렇게 \(MLE\)는 0.4가 됩니다.
3. 가능도에 따른 변수 선택법
위에서 다뤘다시피 로그가능도함수 값은 주어진 데이터에 대한 가능성의 척도이고 ’적합도(goodness of fit)’의 관점으로 바라보면 MLE는 주어진 데이터에 대한 적합도를 높게하는 추정량이라고 말씀드렸습니다. 이는 모형에도 그대로 적용됩니다. GLM은 모형의 모수를 최대가능도법으로 구하기 때문에 주어진 데이터에 대한 적합도가 더 높을수록 더 높은 로그가능도함수 값을 갖게 됩니다. 이는 단순히 말해서 로그우도함수 값이 높을수록 추정된 직선 혹은 곡선이 데이터들을 가깝게 지나간다는 의미입니다. 그렇기에 선택된 모형마다 로그가능도 값은 다 다를 것이고 모형 적합에 사용된 예측자마다도 전부 다를 것입니다. 이를 이용하면 어떤 모형을 적용할지 예측자의 조합별로 가장 최적의 모형을 선택할 수도 있습니다.
그렇지만 로그가능도함수 값이 올라가는 것만 보고 무조건 좋은 모형이라고 판단할 수는 없습니다. 그 이유는 바로 변수가 추가되면 항상 높아지는 로그가능도함수의 구조 때문입니다. 로그가능도함수는 예측자가 늘어날수록 낮아지지는 않고 항상 증가합니다. 다만 영향도에 따라 더해지는 값이 다를뿐입니다. 그렇기 때문에 각 예측자가 추가되었을 때 증가되는 로그가능도함수 값이 유의미한지를 보아야합니다. 그 이유는 유의한 증가를 보여주지 못함에도 불구하고 예측자를 추가하는 것은 굳이 필요없는 추정을 한 번 더 하는 것이기 때문입니다. 불필요한 추정과 다른 예측자와의 관계를 고려하여 모형은 최대한 간단한 것이 좋습니다. 이를 모형의 모수 절약의 원칙이라 부릅니다.
로그가능도함수 값을 이용하여 모형을 비교할 수 있는 척도는 여러가지가 있습니다. 대표적으로 이탈도(deviance)라고 불리는 두 모형의 로그가능도함수 값의 차이가 유의한지 보는 것과 로그가능도함수 값과 모형에 사용된 모수의 수를 동시에 고려한 AIC가 있습니다. 이 중에 많이 사용되는 AIC에 대해 다루겠습니다.
AIC는 로그가능도함수 값이 높으면 가산점을 주고 모형에 사용된 모수가 많으면 패널티를 주는 형식으로 만들어진 척도로 작으면 작을수록 바람직한 모형이라고 판단합니다. 정리하면 다음과 같습니다.
\[ AIC=-2(log\; likelihood-number\; of\; parameters \;in \;model)\\ = - 2 \; log\; likelihood + 2number\; of\; parameters \;in \;model \] 예를 들어, 2개의 모형 모수를 이용한 모형의 로그가능도함수 값이-16이고 4개의 모수만을 이용한 모형의 로그가능도함수 값은 -15이라고 했을 때 각 모형의 AIC는 각각 36과 38입니다. 비록 로그가능도함수 값은 두 번째 모형이 더 컸지만 모형에 사용된 모수가 더 많아 첫 번째 모형애 비해 바람직하지 않다는 판단을 할 수 있습니다. AIC를 평가하는 절대적인 기준은 없습니다. 오직 모형 비교 통시에만 활용이 가능한 척도입니다.
이러헌 deviance 혹은 AIC를 이용하면 각각의 예측자를 추가했을 때 그 예측자가 과연 필요한 것인가를 판단할 수 있습니다. 이를 변수 선택이라 하며 그 방법으로 크게 3가지가 있습니다.
전진 선택법(Forward)
전진선택법이라고도 불리는 포워드방법은 기본 모형(basic model)에서부터 가장 큰 영향을 보여주는 예측자를 차례대로 모형에 넣어서 그 유의미함을 판단한는 방법입니다. 여러 과정을 거친 후 추가된 예측자가 더이상 유의하지 않다면 제거 후 포워드 방법을 멈추게 됩니다.
후진 제거법(Backward)
후진제거법인 백워드 방법은 포워드와는 반대로 가장 복잡한 모형(full model)에서 시작으로 가장 유의미하지 않는 예측자 부터 차례대로 제거해 나갑니다. 여러 과정을 거친 후 제거된 예측자가 유의미한 것으로 판단되면 추가 후 백워드 방법을 멈추게 됩니다.
단계별 선택법(Stepwise)
스텝와이즈는 두 방법의 단점을 보완한 방법으로, 전진선택을 하면서 각 단계마다 후진제거를 할 것인지 체크하게 됩니다. 포워드와 백워드는 한 번 추가되거나 제거된 예측자에 대해서는 더이상 신경쓰지 않는 반면 스텝와이즈 방법은 새로운 예측자가 들어갔을 때 전 단계에서 모형에 포함된 예측자가 무의미해진다면 제거할 수 있습니다. 이는 예측자 사이의 관계 때문으로 원래는 유의했던 예측자가 다른 예측자가 포함됨에 따라 그 영향도가 바뀔 수 있다는 데에 착안해 고안된 방법입니다.
변수 선택법을 R에서 구현하는 방법은 다음과 같습니다.
x1 = runif(n = 1000,min = -10, max = 10)
x2 = runif(n = 1000,min = -10, max = 10)
x3 = runif(n = 1000,min = -10, max = 10)
x4 = runif(n = 1000,min = -10, max = 10)
x5 = runif(n = 1000,min = -10, max = 10)
y = 0.1 * x1 - 0.7 *x3 + runif(n = 1000, min = -1, max = 1)
Reg = step(lm(y ~ x1 + x2 + x3 + x4 + x5),direction = "backward")Start: AIC=-1046.68
y ~ x1 + x2 + x3 + x4 + x5
Df Sum of Sq RSS AIC
- x4 1 0.2 347.1 -1048.14
- x2 1 0.4 347.3 -1047.52
- x5 1 0.6 347.6 -1046.83
<none> 346.9 -1046.68
- x1 1 314.5 661.4 -403.35
- x3 1 16126.2 16473.1 2811.73
Step: AIC=-1048.14
y ~ x1 + x2 + x3 + x5
Df Sum of Sq RSS AIC
- x2 1 0.4 347.5 -1048.98
- x5 1 0.6 347.7 -1048.33
<none> 347.1 -1048.14
- x1 1 314.4 661.5 -405.31
- x3 1 16131.5 16478.6 2810.06
Step: AIC=-1048.98
y ~ x1 + x3 + x5
Df Sum of Sq RSS AIC
- x5 1 0.6 348.1 -1049.16
<none> 347.5 -1048.98
- x1 1 316.3 663.8 -403.72
- x3 1 16147.5 16495.0 2809.06
Step: AIC=-1049.16
y ~ x1 + x3
Df Sum of Sq RSS AIC
<none> 348.1 -1049.16
- x1 1 315.9 664.0 -405.49
- x3 1 16152.1 16500.2 2807.37summary(Reg)Call:
lm(formula = y ~ x1 + x3)
Residuals:
Min 1Q Median 3Q Max
-1.02878 -0.51611 -0.01759 0.51527 1.02430
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.001265 0.018693 -0.068 0.946
x1 0.097125 0.003229 30.076 <2e-16 ***
x3 -0.701708 0.003263 -215.074 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5909 on 997 degrees of freedom
Multiple R-squared: 0.979, Adjusted R-squared: 0.9789
F-statistic: 2.322e+04 on 2 and 997 DF, p-value: < 2.2e-16- lm() 명령어에 step()을 덮어주면 자동으로 변수선택법에 따라 변수 선별을 진행합니다.
변수 선택법은 필요한 변수만 뽑아주는 매우 효과적인 방법이지만, 변수들 간의 선형관계가 존재하는 다중공선성을 통제할 수는 없습니다. 다음 장에서는 고차원에서 다중공선성을 제어하며 차원 축소를 하는 방법에 대해 다루도록 하겠습니다.
2. 주성분 분석
대부분의 통계분석은 예측자들이 서로 독립이라는 기본적인 가정을 가지고 있습니다. 그렇기 때문에 예측자를 ’독립변수’라고 표현하기도 하며 각 예측자들의 통계적인 분포는 고려하지 않습니다. 그런데 실제로는 그렇지 않은 경우가 대부분입니다. 경우에 따라 예측자들은 크고 작은 관계를 가지고 있고 그 정도가 심하면 분석 결과를 신뢰할 수 없는 상황에 놓이게 됩니다. 이것을 다중공선성(multicollinearity)이라 부르며 다중공선성이 존재함에도 불구하고 모형을 적합하게되면 각 예측자의 기울기의 분산이 비정상적으로 높아지는 등의 문제가 발생할 수 있습니다. 이는 예측자가 많아질수록 더 큰 문제로 다가오는데, 예측자가 두 개인 경우, 서로에 대한 상관관계만을 갖지만 예측자가 늘어날수록 그 조합에 따라 매우 많은 상관관계를 고려해야하기 때문입니다.
이 문제를 해결하기 위한 방법으로는 여러 가지가 있지만 그 중 가장 대표적으로 사용되는 것이 주성분 분석(principal component)입니다. 주성분 분석은 예측자의 선형조합을 통하여 서로 독립적인 인공변수들을 만들어내는 방법으로, 통계 분석에 사용되는 가장 이상적인 변수를 생산해낸다는 점에서 매우 유용한 방법이라고 할 수 있습니다. 또한 이 과정에서 변수들이 가지고 있는 파워를 소수의 인공 변수로 몰아주어, 분석에 사용되는 변수를 줄여주는 효과를 볼 수 있습니다. 이를 ‘차원축소’ 라고 표현하며 다중공선성과 더불어 통계 분석에서 아주 중요하게 취급되는 주제입니다. 이번 챕터에서는 이 두 가지 관점에서 주성분 분석의 방법론을 다루도록 하겠습니다.

왼쪽의 그래프를 보면 \(X_1\) 과 \(X_2\)라는 변수가 높은 상관관계가 있음을 알 수 있고 이러한 상관성이 다중공선성의 일이킬 수 있다는 것을 상술하였습니다. 같은 포인트를 유지하면서 상관성을 무시하기 위해서는 새로운 축이 필요합니다.
우측의 그래프를 보면 새로운 축 \(P1\)과 \(P2\)에서는 데이터가 상관성을 잃습니다. 이런 식의 직교회전은 원 변수들의 선형결합을 통해 이루어지며, 선형결합의 계수는 변수들의 공분산(상관성)의 구조를 분해하여 얻어지는 고유벡터(eigen vectors)들에 의해 결정됩니다. 직교회전을 하게 되면 두 변수는 통계적으로 독립이되며 다중공선성의 문제를 완벽히 해결할 수 있습니다. 주성분 분석은 이러한 방식으로 직교하는 새 축을 만들어내는 것이 목표입니다.
위 그래프는 두 개의 변수에 대한 축 회전을 표현하지만 두 개가 아닌 3차원 혹은 4차원에서도 이러한 직교회전이 가능하고 그 경우 모든 변수가 서로 독립이 됩니다.
또한 새 주성분 축들은 변수들의 변동을 설명하는 양에 따라 만들어지는 순서가 결정됩니다. 위 그래프를 보면 \(P2\)축의 평행적인 방향보다는 P1축 방향에서 변수들의 변동이 많습니다. 이는 \(X_1\) ,\(X_2\) 가 가지고 있던 변동을 \(P1\) 축보다 \(P2\) 축이 더 많이 설명할 수 있다는 뜻입니다. 이를 직관적으로 이해하기 위하여 다음의 그림을 봅시다.

위 그래프는 변수들이 보이는 변동을 시각화한 것으로, 주성분 축들은 타원의 끝과 끝을 이어주는 방향으로 회전될 것입니다. 각 주성분이 설명할 수 있는 변동의 크기는 주황색과 빨간색의 각 길이로 판단될 수 있으며, 이는 변수들의 공분산(상관성)의 구조를 분해하여 얻어지는 고유값(eigen value)에 비례합니다. 즉, 빨간색 방향으로 먼저 1번 주성분 축이 생성되며 1번 주성분 축과 직교하면서 그 다음으로 변동을 많이 설명할 수 있는 주황색 방향으로 2번 주성분 축을 생성하게 됩니다.
이와 같은 특성으로 인해 주성분 분석을 사용하면 합리적인 차원축소를 가능해집니다. 이해를 위해 조금은 극단적인 예를 보겠습니다.

위와 같은 데이터가 있을 경우 데이터의 포인트들을 사용하지 않고 빨간색 선 위의 점을 대신 사용해도 무방할 것으로 보입니다. 그 이유는 빨간색 선 방향으로만 큰 변동을 보이고 다른 방향으로는 거의 변동이 없기 때문이죠.
즉, 굳이 \(X_1\) 과 \(X_2\) 두 변수를 사용하지 않고 저 선위의 점들만 사용하면 2개의 변수를 하나의 변수로 줄이는 효과를 볼 수 있습니다. 이는 곧 2차원에서 1차원으로의 차원축소를 의미합니다.
\(k\)차원의 경우에도 마찬가지입니다. 주성분 분석을 진행하면 \(k\)개의 서로 직교하는 새로운 축을 생성하지만 처음으로 생성되는1번 주성분 축이 가장 큰 변동을 설명하고 마지막에 생성되는 \(k\)번 주성분 축이 가장 적은 변동을 설명하게 됩니다. 또한 모든 축이 설명하는 변동은 \(k\)개의 원래 변수가 가지고 있던 변동의 전부를 설명합니다. 이런 점을 미루어 볼 때, 분석자는 \(k\)개의 새로운 축 중 만족하는 수준의 변동을 설명할 수 있는 소수의 축만 선택하고 소량의 변동만을 설명하는 축들은 버림으로써 차원을 축소할 수 있는 것이죠. 10개의 변수가 있을 때, 주성분 분석을 시행하면 10개의 축을 얻을 수 있고 이 중 3의 축이 설명하는 변동이 전체의 80%라면, 3번 주성분 축까지만 택하고 나머지 7개 방향의 변동은 무시함으로써 10차원에서 3차원으로의 차원축소가 가능한 것입니다. 또한 이 설명 비율은 위에서 언급한 고유값과 관련이 있습니다.
이 방법들은 전부 원 변수들의 선형결합으로 제시되는 새 주성분 인공 변수를 통해 이루어집니다.
예를 들어 \(X_1 \sim X_5\)의 5개의 변수가 있을 때 주성분 분석을 하게되면 다음과 같은 주성분 변수와 전체 변동의 설명 비율을 구할 수 있습니다.
\(P_1 = 0.2X_1 + 0.1X_2 +0.6X_3 +0.15X_4 - 0.4X_5\) 전체 변동 중 78% 설명
\(P_2= -0.1X_1 + 0.4X_2 +0.12X_3 +0.25X_4 - 0.3X_5\) 전체 변동 중 15% 설명
\(P_3 = 0.31X_1 + 0.13X_2 +0.19X_3 +0.22X_4 - 0.39X_5\) 전체 변동 중 4% 설명
\(P_4 = -0.14X_1 - 0.57X_2 +0.66X_3 -0.05X_4 +0.1X_5\) 전체 변동 중 2% 설명
\(P_5 = 0.42X_1 + 0.02X_2 +0.4X_3 +0.57X_4 + 0.13X_5\) 전체 변동 중 1% 설명
이 경우 두 인공 변수 \(P_1\) , \(P_2\) 만 택하여도 전체 변동의 약 93%를 설명하면서 서로 독립적인 2개의 인공 변수를 얻게 됩니다. 이 선형결합을 통해서 구해진 값을 주성분 점수(principal score)라고 부르며 원 변수를 새 축의 관점에서의 바라보는 값이 될 것입니다. 주성분 점수와 원 변수의 상관계수 혹은 선형 결합의 계수를 이용하면 각 주성분 변수에 작용하는 원 변수의 영향을 알 수 있습니다. 만약 \(X_3\)과 \(P_1\) 의 상관성이 높은 양의 값으로 나타났다면 첫 번째 주성분 \(P_1\) 은 \(X_3\)이 증가하면서 증가하는 것을 알 수 있고 이는 \(P_1\)을 만드는데 \(X_1\) 의 영향이 컸음을 뜻합니다.
또한 이 주성분 점수 값은 완전 독립적인 예측자로써, 회귀분석을 포함한 다른 기타 통계분석에 활용할 수 있습니다.
2. 주성분 분석(R Code)
주성분 분석은 FIFA 18 게임 데이터 셋을 이용하여 분석을 진행하겠습니다.
데이터 전처리
### Principal Component Analysis
library(tidyr)
library(data.table)
FIFA = read.csv("F:\\Dropbox\\DATA SET(Dropbox)\\CompleteDataset.csv", header = TRUE,
stringsAsFactors = FALSE)
FIFA_FIELD = subset(FIFA, FIFA$Preferred.Positions != "GK ")
library(purrr)
FIFA_FIELD2 = FIFA_FIELD[1:100, c(2, 10:40, 42:48, 61:71)]
FIFA_FIELD2 = FIFA_FIELD2 %>% map_if(is.character, as.numeric)
FIFA_FIELD2 = FIFA_FIELD2 %>% map_if(is.integer, as.numeric)
FIFA_FIELD2 = as.data.frame(FIFA_FIELD2)
rownames(FIFA_FIELD2) = FIFA_FIELD$Name[1:100]- 선수들의 능력치를 추출하였습니다.
- 선수들이 많기 때문에 상위 100명에 대해 분석을 진행합니다.
데이터 표준화
데이터의 기하적인 특성을 이용하는 분석은 항상 표준화(Scaling)를 진행해야 합니다. 위에서 설명했듯이 주성분 분석은 데이터의 변동을 기준으로 주성분이 만들어집니다. 만약 단위가 큰(분산이 큰) 변수와 단위가 작은(분산이 작은)변수가 같이 주성분 분석에 투입될 경우, 단위가 큰 변수가 단위가 작은 변수의 변동을 덮어버려 효과를 볼 수 없게 결과값을 왜곡하게 됩니다. 그렇기에 기하성질을 띄는 분석은 단위를 통일시켜주는 표준화작업을 먼저 진행해야됩니다.
SCALED=as.data.frame(scale(FIFA_FIELD2[,1:34]))- scale()을 쓰면 수치형으로 되어 있는 모든 변수들이 평균은 0, 분산은 1을 가지도록 표준화 변환이 진행됩니다.
- 참고로 분석은 포지션별 능력치를 제외한, 피지컬 및 테크닉 능력치들을 분석 대상으로 하겠습니다.
주성분 분석
주성분 분석을 진행하기 전에, 먼저 변수들이 선형관계를 어느 정도 가지고 있는지에 대해서 탐색을 할 필요는 있습니다. 만약, 변수 간의 상관관계가 적은 경우, 굳이 주성분 분석을 할 이유는 크게 없기 때문입니다. 차라리 전에 언급한 변수선택법을 통해 차원(변수)을 줄여가는 것이 더 효과적입니다.
library(corrplot)
library(RColorBrewer)
Corr_mat = cor(SCALED)
corrplot(Corr_mat, method = "color", outline = T, addgrid.col = "darkgray",
order = "hclust", addrect = 4, rect.col = "black", rect.lwd = 5, cl.pos = "b",
tl.col = "indianred4", tl.cex = 0.5, cl.cex = 0.5, addCoef.col = "white",
number.digits = 2, number.cex = 0.3, col = colorRampPalette(c("darkred",
"white", "midnightblue"))(100))
- cor()은 상관행렬을 만드는 명령어입니다.
- 변수들간의 선형관계가 꽤나 높은 것을 알 수 있습니다.
주성분 분석을 통해 차원축소를 진행하겠습니다.
library(factoextra)
library(FactoMineR)
Principal_Component = PCA(SCALED,graph = FALSE)- PCA()는 주성분 분석을 실행하는 코드입니다.
- graph = FALSE 옵션은 PCA() 명령어를 통해 자동으로 출력되는 그래프가 출력되지 않도록 하는 옵션입니다.
- 가장 먼저 확인해야 되는 부분은 새로 만들어진 주성분들이 변수들의 변동을 얼만큼 설명하고 있는지를 확인해야 됩니다.
Principal_Component$eig[1:5,] eigenvalue percentage of variance cumulative percentage of variance
comp 1 14.894127 43.806256 43.80626
comp 2 3.600039 10.588349 54.39461
comp 3 2.975834 8.752452 63.14706
comp 4 2.480377 7.295227 70.44228
comp 5 2.002131 5.888621 76.33090- comp1(제 1주성분, PC1)은 전체 변동의 43.80%를 설명합니다.
- comp2(제 2주성분, PC2)은 전체 변동의 10.58%를 설명하며, 제 1주성분을 포함한 누적 설명력은 54.39%입니다.
Scree plot은 각 주성분이 전체 변동에 대해 설명하는 비율을 나타냅니다.
fviz_screeplot(Principal_Component, addlabels = TRUE, ylim = c(0, 50))
-
PC1이 가장 많은 변동을 설명하며, PC7부터는 설명하는 비율의 변화가 매우 작은 것을 볼 수 있습니다.
-
Scree Plot을 통해 몇 개의 주성분까지 가져다 사용할 것인지 판단하는 것이 주성분 분석의 첫번째 단계입니다.
-
주성분 가중치 확인
-
주성분 분석의 해석은 각 주성분에서 어떤 변수가 가장 큰 영향력을 가지고 있는지 파악하는 것입니다.
-
(+)라고 좋은 것이 아니며, (-)라고 나쁜 것이 아닙니다. 부호는 방향을 의미합니다.
-
영향력 자체는 계수의 절댓값 크기에 집중을 해야합니다.
-
Dim.1은 제 1주성분(PC1)을 의미합니다.
Principal_Component$var$coord[1:34, ] Dim.1 Dim.2 Dim.3 Dim.4
Age -0.1391304 0.15188183 0.0002134079 0.43702597
Acceleration 0.6111358 -0.41547597 -0.0837865360 -0.44590706
Aggression -0.6583780 0.15278535 0.3071821747 0.17498731
Agility 0.8041455 -0.01336877 -0.0545868730 -0.36064461
Balance 0.6044207 0.15321777 -0.2446476197 -0.48091951
Ball.control 0.9140783 0.21037964 0.0194490653 -0.06052152
Composure 0.4190301 0.25451272 -0.0022204597 0.50070532
Crossing 0.8198600 0.25508545 -0.0058704866 -0.10857638
Curve 0.9155934 0.20091316 -0.0366767330 -0.02629993
Dribbling 0.9389829 0.04414586 -0.0944411585 -0.11187542
Finishing 0.9035608 -0.17998183 0.1005064965 0.18373436
Free.kick.accuracy 0.8181311 0.29463438 0.0920612901 0.06445744
GK.diving 0.1498721 -0.05724641 0.6802467984 -0.22159550
GK.handling 0.1079801 -0.05885318 0.6748930563 -0.16986119
GK.kicking 0.2176676 -0.08598534 0.7173101651 -0.16002126
GK.positioning 0.0916075 -0.13699776 0.6715493703 -0.11918837
GK.reflexes 0.2013511 -0.14807891 0.7759962774 -0.10869070
Heading.accuracy -0.5371602 -0.32424989 0.1744474398 0.59771117
Interceptions -0.7197588 0.58103933 0.1157715176 -0.07256358
Jumping -0.4587959 -0.35864751 0.0540112040 0.29396321
Dim.5
Age -0.080699184
Acceleration 0.380635869
Aggression 0.379845386
Agility 0.261068995
Balance 0.218730455
Ball.control 0.008509720
Composure 0.008980891
Crossing 0.169537864
Curve 0.024764215
Dribbling 0.039338751
Finishing -0.019721032
Free.kick.accuracy -0.012611936
GK.diving -0.123443113
GK.handling -0.257640855
GK.kicking 0.023624321
GK.positioning -0.086825626
GK.reflexes -0.153215026
Heading.accuracy 0.237293106
Interceptions 0.220703722
Jumping 0.558884296
[ getOption("max.print") 에 도달했습니다 -- 14 행들을 생략합니다 ]\[ PC1 =-0.14*Age+0.61*Acceleration-0.65*Aggression+\\ 0.8*Agility+0.6*Balance+0.91*Ball.control + \cdots+0.89*Volleys \]
다음과 같은 변수들의 선형결합꼴로 나타낼 수 있습니다. 제 2주성분(PC2)는 다음과 같습니다.
\[ PC2 =0.15*Age-0.42*Acceleration+0.15*Aggression-\\ 0.013*Agility+0.15*Balance+0.21*Ball.control + \cdots-0.07*Volleys \]
-
제 1주성분에서의 변수들의 가중치를 살펴보면 다음과 같습니다.
-
Ball.control, Curve, Dribbling, Finishing, Volleys 변수의 가중치가 0.9 전후로 양의 방향으로 가중치가 큰 것을 알 수 있습니다.
-
Aggression, Interceptions, Marking, Sliding tackle, Standing.tackle 등의 변수는 -0.7 전후로 음의 방향으로 가중치가 큰 것을 확인할 수 있습니다.
-
분석한 가중치를 토대로 주성분에 대해 새로운 이름을 만들어줘야 합니다.
-
PC1이 양의 방향으로 큰 경우는 일반적으로 공을 다루는 능력치들이 좋은 경우에 해당됩니다.
-
반대로 PC1이 음의 방향으로 큰 경우는 일반적으로 수비 능력치가 높을 경우에 해당됩니다.
-
즉, PC1은 수비 포지션 여부라는 새로운 이름을 지어줄 수 있습니다.
수 많은 변수를 분석한 주성분 계수는 눈으로 확인하기 힘든 경우가 많습니다. 그렇기에 Biplot이라는 그래프를 그려 효율적으로 확인하고자 합니다.
fviz_pca_var(Principal_Component, col.var = "contrib", gradient.cols = c("#00AFBB",
"#E7B800", "#FC4E07"), repel = TRUE # Avoid text overlapping
)
-
Biplot의 x축은 Dim1(제 1주성분), y축은 Dim2(제 2주성분)입니다.
-
예를들어 Long.passing 변수의 가중치는 제 1주성분에서 0.30입니다. 제 2주성분에서의 가중치는 0.82입니다.
-
Biplot에서 Long.passing 변수는 \((0.30,0.82)\)에 찍히게 됩니다.
-
Biplot에서 같은 방향으로 뻗어나가는 변수일수록 비슷한 변수들이라고 볼 수 있습니다.
-
Biplot을 통해 확인할 수 있는 분석 결과는 PC1이 크거나 작을 경우에는 어떤 변수들이 영향을 많이 미치는지, 혹은 PC2가 클 때, 작을 때 어떤 변수들이 영향을 많이 주는지 가중치를 한 눈에 확인하는 것입니다.
추가적으로 주성분 분석은 고차원의 변수들을 단 2차원의 그래프로 시각화해주는 뛰어난 효율성을 지니고 있습니다. 그렇기에 주성분 분석은 시각화 목적으로도 자주 쓰이고는 합니다.
fviz_pca_biplot(Principal_Component, repel = FALSE)
-
위에서 그렸던 Biplot위에다가 선수들의 산점도를 같이 그렸습니다.
-
각 선수들별로 새로운 변수(주성분)에 대한 값이 계산이 되어 있습니다. 이런식으로 크리스티아노 호날두 선수는 Biplot상에서 \((4.95,-1.72)\)에 위치하게 됩니다.
-
각 선수들의 능력치 분포와 상대적 위치를 확인할 수 있습니다.
주성분 분석은 이렇게 기존 변수들의 선형 결합을 이용하여 새로운 축(변수)를 만듭니다. 그리고 새로운 변수 값을 이용하여 분석을 새로 진행하게 됩니다. 각 주성분 간의 상관계수는 0이기 때문에 주성분 값으로 회귀분석을 진행하게 될 경우, 다중공선성을 걱정하지 않아도 됩니다. 또한 효과적인 차원축소로 모델을 간단하게 만들 수 있습니다. 주성분 분석은 기계학습에서도 주로 쓰이는 차원축소 방법입니다. 주성분 분석을 한번에 이해하기는 매우 힘듭니다. 그러기에 많은 해석 연습이 필요한 부분입니다.
3. 군집분석
군집분석이란 데이터들을 서로 비슷한 데이터들끼리 묶어주어, 여러 개의 군집으로 묶어 주는 분석입니다. 이제까지 진행했던 분석들은 ‘지도 학습(Supervised Learning)’이라고 합니다. 구해야 되는 값이 명확하기 때문입니다. 군집분석은 반대로 ‘비지도학습(Unsupervised Learning)’입니다. 구해야 되는 값이 명확하지 않기 때문입니다. 예를 들어, 카드사에서 고객들의 특성을 파악하여 비슷한 고객들을 대상으로 군집을 형성하려고 합니다. 이 때, 카드사는 고객들을 어떻게 분류해야되는지 기준이 없기 때문에 구해야 되는 값이 명확하지 않습니다. 이럴 때 군집분석은 매우 유용하게 사용됩니다.
먼저, 군집분석에서는 유사도(Similarity)개념이 공통적으로 쓰입니다.
유사도(Similarity)
단어의 의미 그대로 ’비슷한 정도’를 의미합니다. 단, 이 유사도를 측정하는 방법은 매우 많습니다. 여기서는 간단한 방법들에 대해만 언급하고 넘어가겠습니다.

-
유클리디안 거리(Euclidean Distance) 좌표상에서 데이터들 간의 직선거리를 의미합니다.
-
코사인 유사도(Cosine Similarity)
좌표상에서 데이터들 간의 Cosine값을 의미합니다. 유클리디안 거리에서는 거리가 가까울 수록, 코사인 유사도에서는 각 데이터 간의 각도가 작을 수록 데이터가 비슷하다는 것을 의미합니다.
군집분석에서 주의해야할 부분은 몇 개의 군집으로 나눌지는 분석가의 판단에 달려 있습니다. 선형 모형에서처럼 p-value가 해결해주는 부분이 없습니다. 그렇기에 분석가의 정확한 해석이 요구되는 분석입니다. 이는 즉 군집분석의 단점으로 귀결이 됩니다.
군집분석은 크게 계층적 군집분석과 비계층적 군집분석으로 나눌 수 있습니다.
4. 계층적 군집분석
계층적 군집분석의 특징은 다음과 같습니다.
- 데이터들 간의 거리행렬을 구합니다.
- 거리행렬에서 규칙에 따라 가장 유사한 데이터들부터 군집을 형성합니다.
- 상대적으로 작은 데이터에 쓰기 알맞습니다.
계층적 군집분석을 진행하기 위해서는 먼저 유사도가 계산이 되어있어야 합니다.

# 유클리디안 거리 계산
Distance_Matrix = dist(x = Iris, method = "euclidean")
Distance_Matrix 10 20 30 40
20 0.7280110
30 0.2236068 0.7211103
40 0.3605551 0.4000000 0.4472136
50 0.2236068 0.5099020 0.3162278 0.1414214min(Distance_Matrix)[1] 0.1414214거리 행렬에서 가장 가까이 존재하는 관측치는 40, 50입니다. 그러면 40, 50은 같은 군집으로 묶이게 됩니다. 최단 거리법은 군집내 관측치와 다른 관측치 간 가장 가까운 관측치를 선택하게 됩니다.
\[ d(40\ 50, 10) = min[d(40,10), d(50,10)] = min(0.36,0.22) = 0.22 \\ d(40\ 50, 20) = min[d(40,20), d(50,20)] = min(0.40,0.51) = 0.40\\ d(40\ 50, 30) = min[d(40,30), d(50,30)] = min(0.44,0.31) = 0.31 \]
그럼 여기서 거리가 가장 가까운 \(10\)이 \((40\ 50)\)군집에 속하게 됩니다. 계층적 군집분석은 이런식으로 서로 유사도가 높은 순서대로 군집을 형성하게 됩니다. 모든 관측치에 대해서 유사도를 계산해야되기 때문에 표본이 클 경우에는 적합하지는 않습니다.
5. 계층적 군집분석(R Code)
주성분 분석에서 예제로 썼던 피파 데이터를 통해 진행하도록 하겠습니다.
library(cluster)
library(factoextra)
C = sample(1:nrow(SCALED), 40, replace = FALSE) # 랜덤하게 40개만 추출
FIFA_SAMPLE = SCALED[C, ]- 100명의 선수들 중 40명을 랜덤으로 뽑아 계층적 군집분석을 진행하겠습니다.
- 코드출처 : http://www.sthda.com/english/wiki/print.php?id=234
res.hk = hkmeans(SCALED[C, ], 3)
fviz_dend(res.hk, cex = 0.6, palette = "jco", rect = TRUE, rect_border = "jco",
rect_fill = TRUE)
- hkmeans()는 계층적 군집분석 명령어입니다.
- 3은 3개의 군집으로 표시하라는 옵션입니다. 만약 4를 주면 4개의 군집으로 색을 구분합니다.
계층적 군집분석은 기본적으로 연산량이 많기에 큰 표본에서는 추천되지 않습니다. 물론 결과값이 덴드로그램을 통해 시각화할 수 있기에, 대표본을 대상으로는 효율적인 방법이 아닙니다. 대신 대표본을 소표본으로 샘플링 한 후, 비계층적 군집분석을 하면 대표본을 대상으로하는 군집분석은 몇 개의 군집이 적합할지 탐색할 수 있습니다.
6. 비계층적 군집분석
비계층적 군집분석은 계층적 군집분석과는 반대로 거리행렬을 이용하지 않고, 대표본에 대해 적합한 분석방법입니다. 대표적으로 K 평균 군집분석이 있습니다.
\(K\) 평균 군집분석은 다음의 순서대로 진행이 됩니다.
- \(K\)개의 군집 수를 사전에 결정합니다.
- 초기 \(K\)의 평균값은 데이터에서 무작위로 선택합니다.
- 선택된 데이터는 각 \(K\)의 중심이 됩니다.
- \(K\)개의 중심으로부터 각 데이터 간의 유사도를 구하고, 유사도가 가장 높은 데이터들을 \(K\)에 할당합니다.
- 각 군집의 중심점을 다시 계산하고 3 ~ 4의 과정을 반복합니다.
fviz_nbclust(SCALED, kmeans, method = "wss") + geom_vline(xintercept = 3, linetype = 5)
- 해당 그래프는 군집의 갯수(x축, Number of cluster k)에 따라 각 군집 안에서 데이터 간의 거리 제곱합을 의미합니다. 값이 작을 수록 군집은 작게 형성되었다는 것을 의미합니다. 하지만, 군집을 너무 많이 나눌 경우에는 해석이 힘들어지기 때문에 적당한 \(K\)개를 정하는 것이 중요합니다.
7. 비계층적 군집분석(R Code)
km.res = kmeans(SCALED, 3, nstart = 25)
fviz_cluster(km.res, data = SCALED) + theme_bw()
-
kmeans()는 K평균 군집분석을 실행하는 명령어입니다.
- 3은 군집의 갯수를 3개로 설정하겠다는 의미입니다.
- nstart 옵션은 kmeans 분석을 25번을 하여, 그 중 분산이 가장 작게 나오는 결과를 분석의 최종결과로 정하겠다는 의미입니다. 앞서 언급했듯이, K 평균 군집분석은 임의적인 위치에서 시작하기 때문에 각 결과마다 다르게 나오는 문제가 존재합니다. 그래서 반복적으로 계산합니다.
-
시각화를 주성분으로 차원축소를 하는 이유는 다음과 같습니다.
plot(SCALED[, 1:5], col = km.res$cluster)
이렇게 각 변수들 간의 개별 산점도로 군집이 잘 묶였는지 시각화 하는 것은 너무나 비효율적이기 때문입니다.
-
위의 군집결과를 확인하시면 공격수, 미드필더, 수비수들이 따로따로 군집이 형성되어 있는 것을 확인할 수 있습니다.
-
각 데이터가 어떤 군집에 속했는지는 다음과 같이 확인할 수 있습니다.
km.res$cluster[1:10]Cristiano Ronaldo L. Messi Neymar L. Su찼rez
2 2 2 2
R. Lewandowski E. Hazard T. Kroos G. Higua챠n
2 2 3 2
Sergio Ramos K. De Bruyne
3 2 8. KNN
kNN(k nearest neighbor algorithm)은 새로운 데이터가 주어졌을 때 기존 데이터 가운데 가장 가까운 k개 이웃의 정보를 기반으로 새로운 데이터의 집단을 예측하는 방법론입니다. kNN의 특징을 정리하면 다음과 같습니다.
- 분류 대상이 정해져있는 지도학습입니다.
- 계산 비용이 높습니다.
- 함수 형태가 정해져 있지 않기에, 별도의 모델을 구축하지 않습니다.
- 두 점간의 거리를 측정하는 방법에 따라 다양한 결과값 도출할 수 있습니다.
- k값이 작으면 noise(이상치 등)의 영향을 크게 받고, 반대로 k가 크게 되면 정상적인 분류에 어려움 발생합니다.
kNN에서 가장 핵심은 k를 어떻게 설정하냐에 따라 결과값이 매우 크게 차이가 날 수가 있습니다. 그렇기때문에 적절한 k를 찾는 것이 kNN의 핵심이라고 할 수 있습니다.
9. kNN(R code)
library(caret)
library(class)
library(gmodels)
library(ggplot2)
data(iris)plot(iris$Sepal.Length, iris$Sepal.Width, col = iris$Species, pch = 19)
legend("topright", legend = levels(iris$Species), bty = "n", pch = 19, col = palette())
normMinMax = function(x) {
return((x - min(x))/max(x) - min(x))
}
iris_norm = as.data.frame(lapply(iris[1:4], normMinMax))normMinMax는 kNN을 진행하기 전에, 각 특성값들의 범위를 0~1로 정규화를 시켜주는 작업입니다. 정규화를 진행하면 단위가 동일하게 되며 비율값으로 표시가 되는 효과가 있습니다.
# Train / Test 데이터 구분
ratio = 0.7
indexes = sample(2, nrow(iris), replace = TRUE, prob = c(ratio, 1 - ratio))
iris_train = iris[indexes == 1, 1:4]
iris_test = iris[indexes == 2, 1:4]
iris_train_labels = iris[indexes == 1, 5]
iris_test_labels = iris[indexes == 2, 5]K = c()
ACC = c()
for(x in seq(1,80,by = 2)){
iris_mdl = knn(train=iris_train, test=iris_test, cl=iris_train_labels, k = x)
CM = confusionMatrix(iris_test_labels, iris_mdl)
accuracy = CM$overall[1]
K = c(K,x)
ACC = c(ACC,accuracy)
}
KNN_Result = data.frame(
K = K,
ACC = ACC
)
ggplot(KNN_Result) +
geom_point(aes(x = K, y = ACC)) +
geom_line(aes(x = K , y = ACC),group = 1) +
scale_x_continuous(breaks = seq(0,80,by = 10)) +
theme_bw() +
guides(col = FALSE)
k가 작을 때는 비교적 잘 맞추지만, k가 매우 커지니 정확도가 떨어지는 것을 확인할 수가 있습니다. 참고로 iris데이터는 연습용 데이터이기에 분류가 매우 잘 되는 편입니다. 그렇기에 kNN이 매우 좋구나 라고 생각하기에는 무리가 있는 데이터 셋입니다.
군집분석은 실제 분석에서 대단히 많이 쓰이는 분석입니다. 복잡한 데이터에 대해 모델링을 하기 위해서는 비슷한 유형별로 분리시킨 후 간단하게 하는 작업이 필수적입니다. 이 때, 데이터의 유사성에 따른 군집분석은 매우 유용하게 사용됩니다.
'MustLearning with R 1편' 카테고리의 다른 글
| 14. 기계학습 (1) | 2020.01.29 |
|---|---|
| 12. 범주형 자료분석 (0) | 2020.01.29 |
| 11. 기초통계이론 2단계 (0) | 2020.01.29 |
| 10. 기초통계 이론 1단계 (1) | 2020.01.29 |
| 9. ggplot2를 활용한 다양한 그래프 그리기 (0) | 2020.01.29 |



